对于图片生成模型来讲,过去正确渲染文本是一个巨大的挑战。如果小标题或文本元素有拼写错误或错误,整个图像都可能变得无法使用。
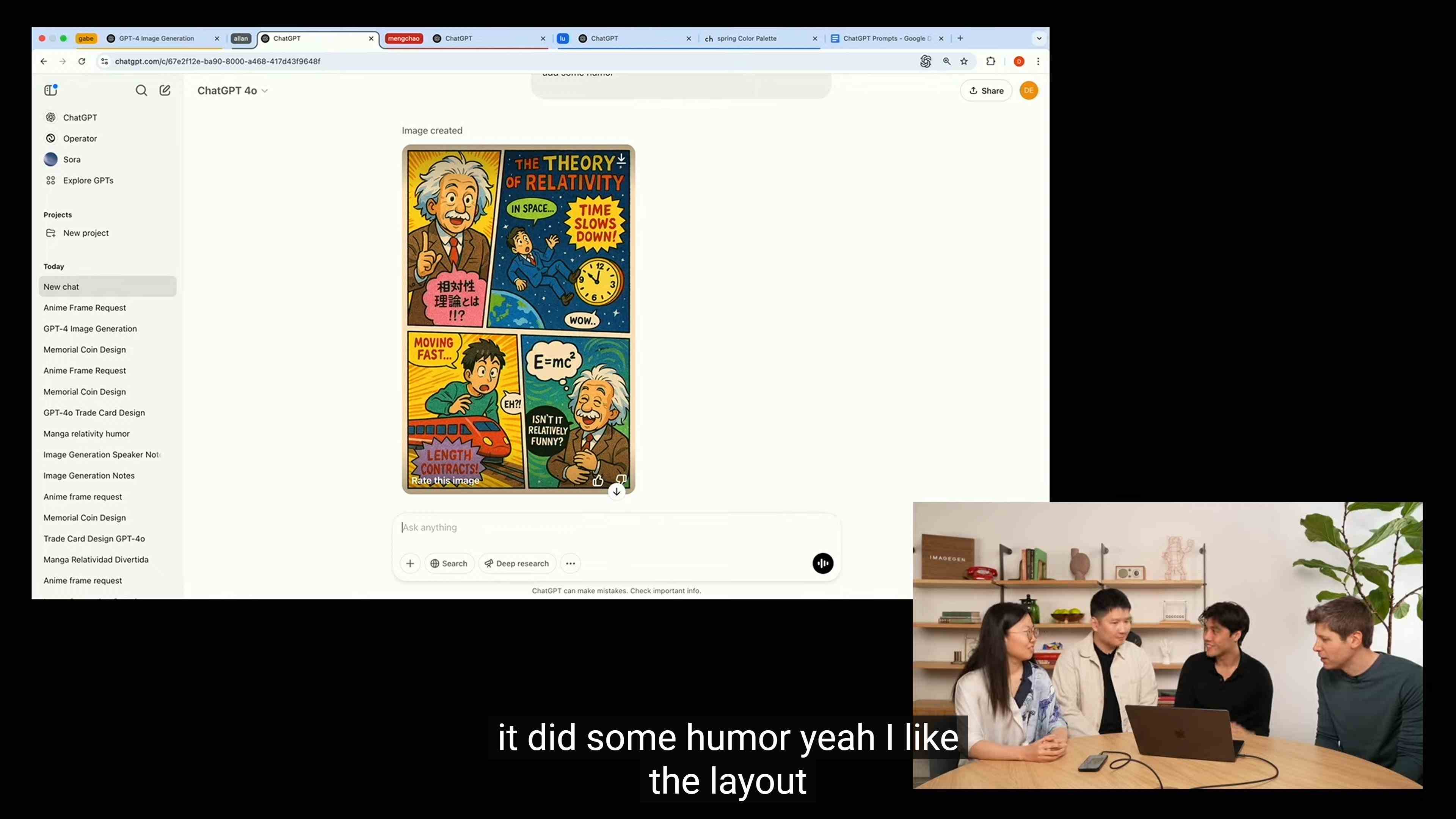
此外在这个案例中,OpenAI 还演示了类似对相对论这样「世界上现有知识」的正确引用。

「如果我画一张图像,我会受到自身技能的限制……以及我积累的所有世界知识的限制,」 ChatGPT多模态产品负责人 Jackie Shannon 在接受媒体采访时解释这个功能的必要性。
「该模型将世界知识代入其中,因此当你要求生成牛顿棱镜实验的图像时,你无需解释「牛顿棱镜实验」这件事它本身是什么,就能得到准确的图像。」

除了上述这些直播中提到的模型能力改进,OpenAI 还表示新版 Sora 大幅提升了在属性和对象之间保持正确关系的能力。例如,绑定能力较差的模型可能会将要求生成蓝色星星和红色三角形的提示词,生成为红色星星而没有三角形。
据 OpenAI 介绍,现有的大多数图像模型在这方面都很容易「犯错」,尤其是当被要求渲染多个项目(通常在5到8个左右)时,经常会混淆颜色和形状。而新版 Sora 的图像生成功能,可以正确绑定15到20个对象的属性,在理解各自的复杂需求的同时,保证不会被误导,从而大幅提高成功率。

除了这些使用体验上的改进,还有一个细节是,OpenAI 已经确认,新版 Sora 生成图像的时间比以前更长,但 OpenAI 认为这是一个值得的权衡。
「虽然我们在延迟方面肯定还有改进的空间……但(我们觉得)这些生成图片的质量、功能和世界知识,确实弥补了用户需要等待的额外几秒钟,」Shannon说。
至于生图领域的安全问题 —— 从去年到今年已经出现多次伪造名人不雅图像、热点事件虚假图像,以及 Google Gemini 去除照片原水印这样的问题,OpenAI 团队强调新版 Sora 已经可以去除照片水印,同时阻止生成性深度伪造图像,并拒绝生成相关的内容请求。同时所有生成的图像都将包含标准的C2PA元数据,以标记该图像是由OpenAI创建的。
目前,新版集成在 ChatGPT 内的 Sora 图像生成模型功能,已经开放给 Pro 和 Plus 订阅套餐的用户,并且 OpenAI 承诺,新版 Sora 也会在不久的将来,提供给免费版本和 API。