通信效率瓶颈:网络通信不稳定,梯度同步瓶颈明显;
可信执行缺失:缺乏可信执行环境,难以验证节点是否真正参与计算;
缺乏统一协调:无中央调度器,任务分发、异常回滚机制复杂。
去中心化训练可以理解为:一群全球的志愿者,各自贡献算力协同训练模型,但「真正可行的大规模去中心化训练」仍是一项系统性的工程挑战,涉及系统架构、通信协议、密码安全、经济机制、模型验证等多个层面,但能否「协同有效 + 激励诚实 + 结果正确」尚处于早期原型探索阶段。
联邦学习(Federated Learning) 作为分布式与去中心化之间的过渡形态,强调数据本地保留、模型参数集中聚合,适用于注重隐私合规的场景(如医疗、金融)。联邦学习具有分布式训练的工程结构和局部协同能力,同时兼具去中心化训练的数据分散优势,但仍依赖可信协调方,并不具备完全开放与抗审查的特性。可以看作是在隐私合规场景下的一种「受控去中心化」方案,在训练任务、信任结构与通信机制上均相对温和,更适合作为工业界过渡性部署架构。
AI 训练范式全景对比表(技术架构 × 信任激励 × 应用特征)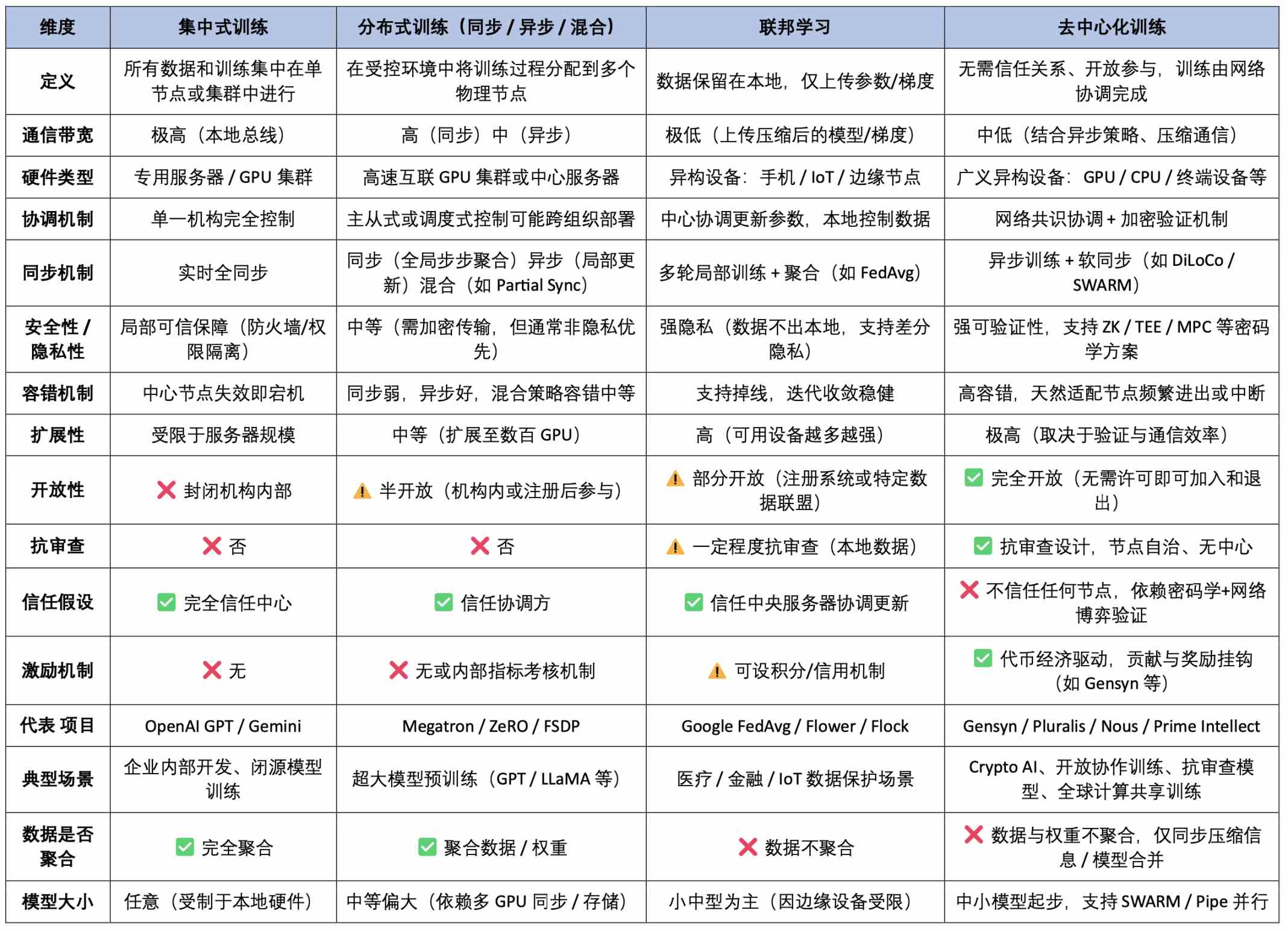
从训练范式来看,去中心化训练并不适用于所有任务类型。在某些场景中,由于任务结构复杂、资源需求极高或协作难度大,其天然不适合在异构、去信任的节点之间高效完成。例如大模型训练往往依赖高显存、低延迟与高速带宽,难以在开放网络中有效切分与同步;数据隐私与主权限制强的任务(如医疗、金融、涉密数据)受限于法律合规与伦理约束,无法开放共享;而缺乏协作激励基础的任务(如企业闭源模型或内部原型训练)则缺少外部参与动力。这些边界共同构成了当前去中心化训练的现实限制。
但这并不意味着去中心化训练是伪命题。事实上,在结构轻量、易并行、可激励的任务类型中,去中心化训练展现出明确的应用前景。包括但不限于:LoRA 微调、行为对齐类后训练任务(如 RLHF、DPO)、数据众包训练与标注任务、资源可控的小型基础模型训练,以及边缘设备参与的协同训练场景。这些任务普遍具备高并行性、低耦合性和容忍异构算力的特征,非常适合通过 P2P 网络、Swarm 协议、分布式优化器等方式进行协作式训练。
去中心化训练任务适配性总览表
