与此同时,为了保证评估过程的准确,评价者不仅需要支付一定费用注册 Topic,还需要额外投入一定数量的代币,若发现评价者作恶,则会面临资产削减(Asset Slashing)的风险。
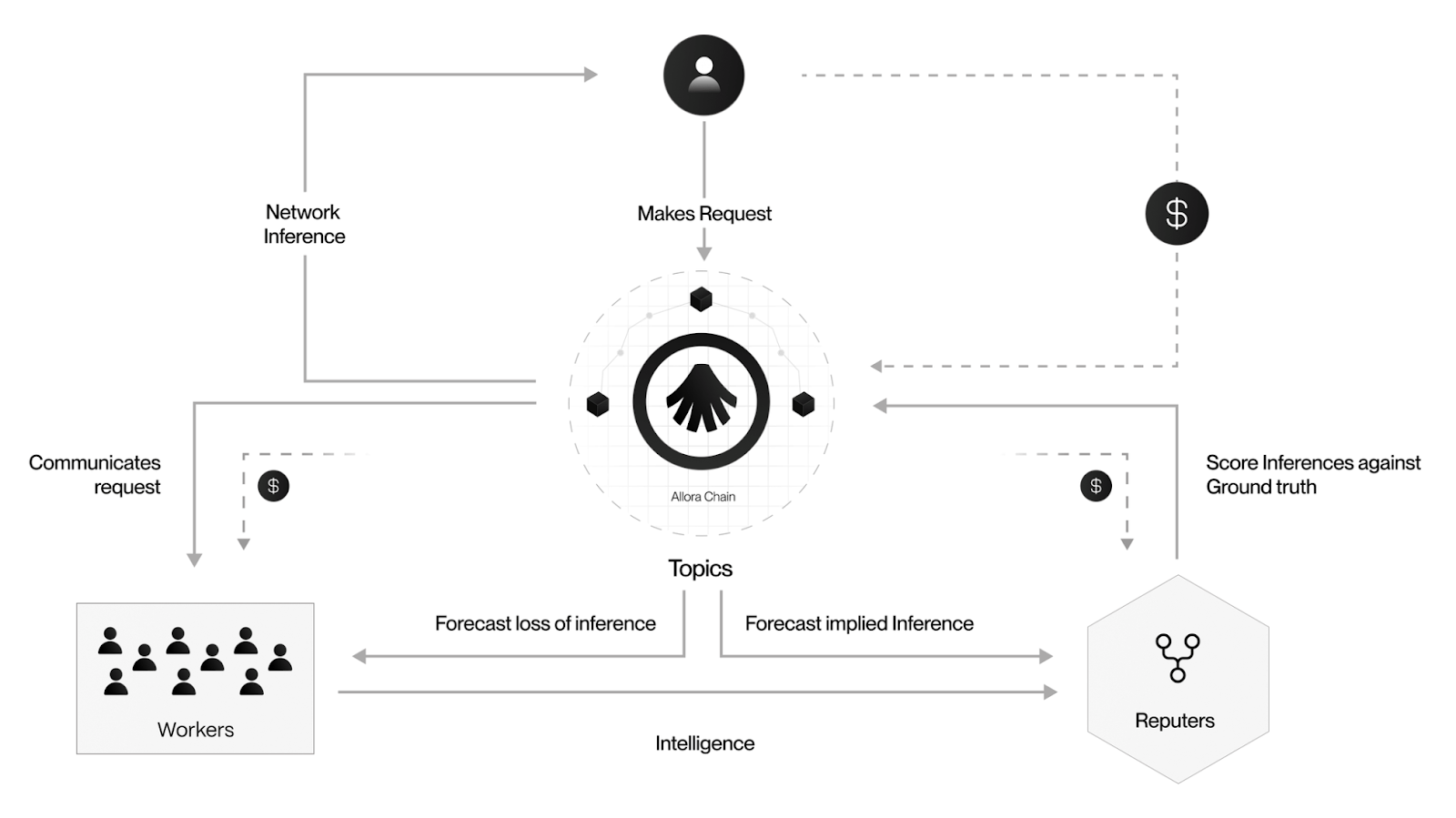
举个例子,当用户发起「预测明天天气」的需求时:
工作者 A 对于天气的平均推论精确度为 90%,但夏季其准确度会下降。
工作者 B 对于天气的平均推论精确度为 88%,但夏季其准确度会上升。
如果当下正处于夏季,多位工作者预测「工作者 A 在夏季约有 10% 的误差」,并同时预测「工作者 B 在夏季约有 5% 的误差」,尽管工作者 A 平均推论精确度更高,Allora 仍会赋予工作者 B 较高权重。
如此一来,Allora 便能够根据当前环境动态调整每个预测的权重,而不是依赖静态或历史数据,这种具有上下文感知的集体推理,使得 Allora 有能力为用户带来更公平、更准确、更能适应复杂需求的输出,同时也为 Allora 的差异化奖励机制打下基础。
作为 Allora 原生代币,$ALLO 是网络激励的核心载体,在网络中具有多重效用:
-
购买推断结果:消费者使用 $ALLO 支付费用获得更精准的推理结果,Allora 采用灵活的「PWYW - 你愿意支付多少」模型,允许消费者自主决定为推理支付的 $ALLO 费用;
-
支付参与费用:使用 $ALLO 代币支付 Allora 中创建 Topic、注册 Topic 等费用,以便更好的参与网络;
-
质押:评价者和网络验证者可以使用 $ALLO 代币进行质押以获得 $ALLO 质押奖励,其他代币持有者也可以将其代币委托给评价者或网络验证者。
-
奖励支付:网络使用 $ALLO 代币向参与者支付奖励。工作者的准确性越高,奖励越丰厚。评价者和网络验证者的奖励与其质押和共识成比例。
差异化奖励机制作为 Allora 的另一大创新,基于实时调整的权重系统,Allora 为不同网络参与者提供定制激励,确保奖励分配给更高质量的贡献,并保证整个运作体系的顶峰性能。
此外,Allora 系统还会计算「如果没有某个工作者的输入结果会如何」的反事实值,确保奖励与贡献的真实信息增益对齐。
构建 AI 多场景落地基础设施:从 DeFAI、RWAFi 到 GameFi聊完产品,更值得聊的是生态。
而聊到生态,Allora 则更显包罗万象:
站在用户角度,Allora 可以为消费者提供更高质量的 AI 服务;
而站在产品角度,开发者可以基于 Allora 提供的去中心化、自我改进的 ML 模型网络等基础设施,构建功能更强大的应用程序,可以在 Allora 上部署模型响应用户需求并获得奖励,实现模型价值代币化,并不断提升模型能力,还可以将现有平台连接到 Allora,将 AI 整合到其应用程序中。