第一步:风险分类标准化——说同一种语言
你不能被工具牵着鼻子走。不同的工具可能会用「Coin Mixer」、「Protocol Privacy」、「Shield」等不同标签来描述同一个风险。如果你的合规官需要记住每个工具的「方言」,那简直是一场灾难。正确的做法是,建立一套内部统一的、清晰的风险分类标准,然后将所有接入工具的风险标签,都映射到你自己的这套标准体系中。
例如,你可以建立如下的标准化分类:
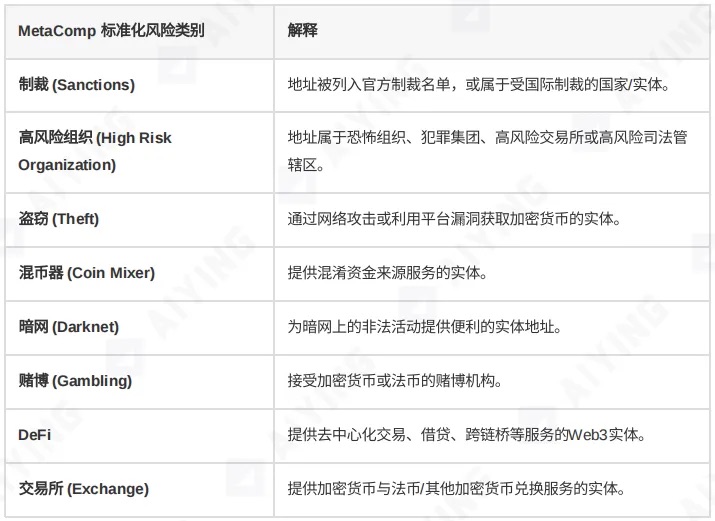
表 1:风险类别映射表示例
通过这种方式,无论接入哪个新工具,你都能迅速将其「翻译」成内部统一的语言,从而实现跨平台的横向比较和统一决策。
第二步:统一风险参数与阈值——划定清晰的红线
有了统一的语言,下一步就是制定统一的「交战规则」。你需要基于自身的风险偏好(Risk Appetite)和监管要求,设定清晰的、可量化的风险阈值。这是将主观的「风险偏好」转化为客观的、可由机器执行的指令的关键一步。
这套规则不应只是简单的金额阈值,而应是更复杂的、多维度的参数组合,例如:
-
严重性级别定义:明确哪些风险类别属于「严重」(如制裁、恐怖融资),哪些属于「高风险」(如盗窃、暗网),哪些属于「可接受」(如交易所、DeFi)。
-
交易层面污染度阈值(Transaction-Level Taint %):定义一笔交易中间接来自于高风险源的资金比例达到多少时,需要触发警报。这个阈值需要通过大量数据分析来科学设定,而非拍脑袋决定。
-
钱包层面累积风险度阈值(Cumulative Taint %):定义一个钱包在其整个交易历史中,与高风险地址的资金往来比例达到多少时,需要被标记为高风险钱包。这能有效识别那些长期从事灰色交易的「老油条」地址。
这些阈值就是你为合规系统划定的「红线」。一旦触及,系统就必须按照预设的剧本进行响应。这使得整个合规决策过程变得透明、一致且可辩护(Defensible)。
第三步:设计多层筛查工作流——从点到面的立体打击
最后,你需要将标准化的分类和统一的参数,整合到一个自动化的多层筛查工作流中。这个流程应该像一个精密的漏斗,层层过滤,逐步聚焦,实现对风险的精准打击,同时避免对大量低风险交易的过度干扰。
一个有效的工作流应该至少包含以下几个步骤:
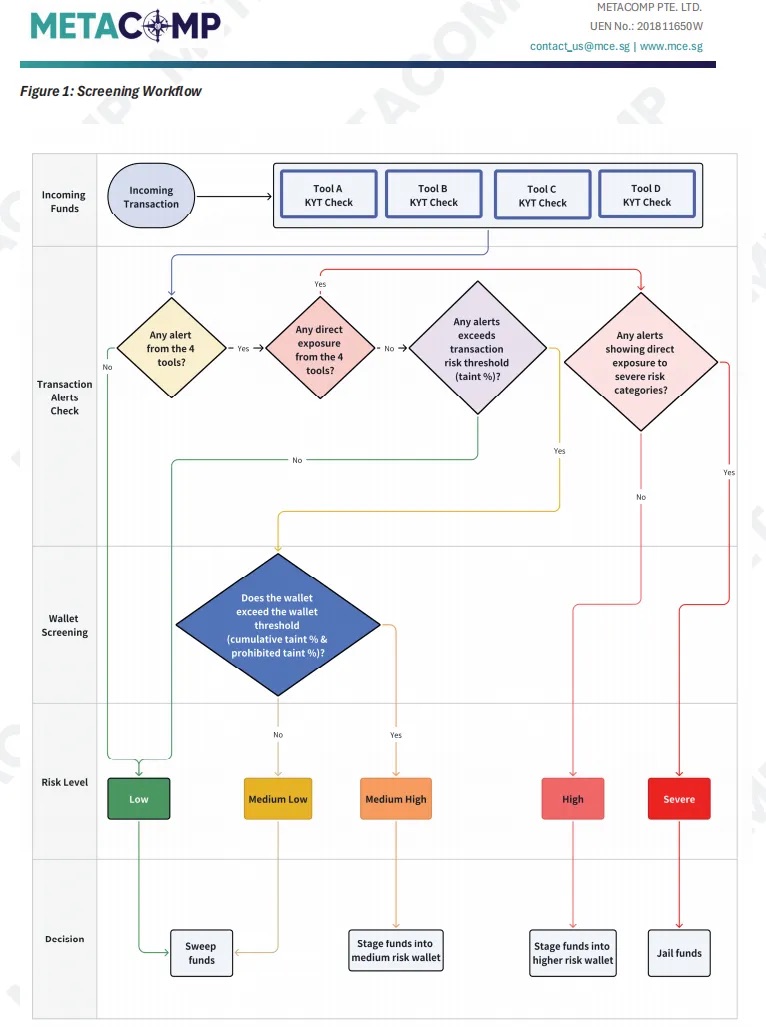
图 4:一个有效的多层筛查工作流示例(改编自 MetaComp KYT 方法论)