其实,「记录一生」这个想法很早就有人提过。
上世纪 90 年代,计算机先驱戈登·贝尔就尝试过全天佩戴相机来记录生活,最后失败了。原因很简单:拍得再多,没有 AI 的辅助,大量素材也很难被整理为真正有用的故事。
而 Looki 的突破在于:多模态 AI。它能理解视觉、声音和语义,让碎片化的素材变成可用的「记忆」。
例如,当我问 Looki,我昨天喝了什么咖啡时,它能够迅速分析录像素材,告诉我分别在哪家店铺,喝了什么口味的咖啡,还会描述一下当时的氛围等等,同时把当时的照片罗列出来。
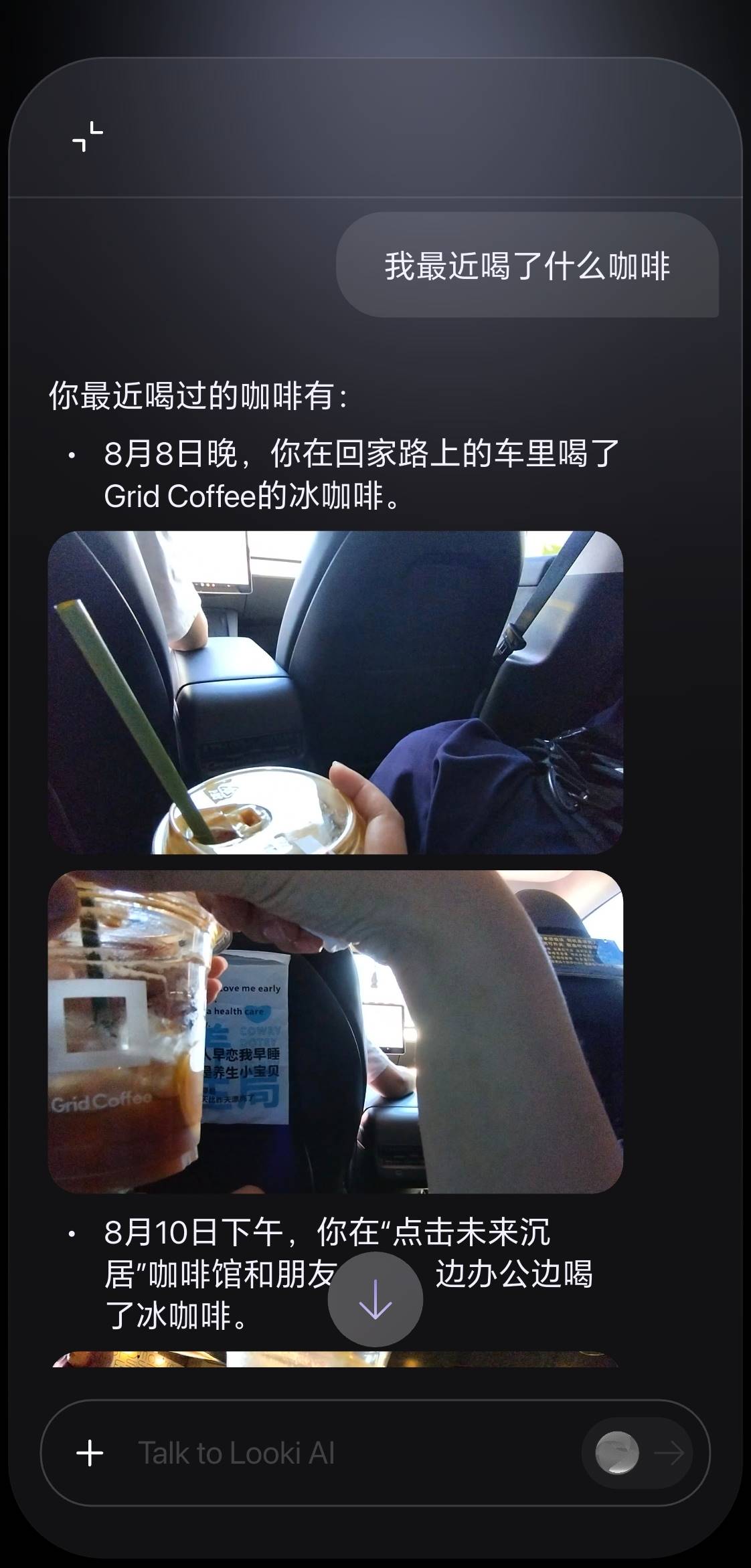
我和 Looki AI 聊天的页面|图片来源:极客公园
有多位创业者曾对我表达过相似的观点,大模型如果想要真正发挥作用,一定要具备对物理世界的感知能力,要具备硬件。这可能也是为什么「随身 AI 硬件」会成为当下创投圈备受关注的热点。
Looki 的创新之处就在于,它率先通过巧妙设计的硬件释放了多模态 AI 的能力,让人们感知到了「多模态 AI」到底能够在现实生活中做到什么,将未来摆在了所有人眼前。
过去,服务于个人生活的 AI 很难做,一个关键原因就是缺少上下文(context)。
Looki 团队告诉我,他们接入的大模型是 ChatGPT 和 Gemini。但是我体验下来,Looki AI 完全优于我使用的网页版的 ChatGPT 和 Gemini,它会更加懂我,更能够结合我的生活来和我聊天。
我想,核心原因,就在于 Looki 的硬件捕捉了我所处的物理环境信息,为 AI 提供了更多上下文。如果没有个性化的上下文,那么 AI 给出的答案往往是正确但无用的。
可以说,Looki 能生成什么内容,基本取决于它拍摄到什么。我带着它去的地方越多,它生成的内容也就越丰富、越深刻。此时,照片、视频不再是终点,而是提示词(Prompt)。有了 Looki L1,整个世界都在成为我的 AI 提示词。
Looki L1 的外形看上去像个外星人,每次戴着它出门,都好像带着一位外星朋友,一同走进这个社会。它会记录我们一起去过的地方,见过的人,经历过的事件。它就像一个和我有着共同经历、总出现在我身边的朋友。它也会随着经历的丰富而成长,会和我形成感官共鸣。
还记得,前段时间 OpenAI 收购了前苹果设计总监 Jony Ive 的公司,目标要改变人和 AI 之间的交互方式,打算在 2026 年推出 AI 硬件,而其概念流出图和 Looki L1 极为相似。
也许,我们今天看到的 Looki L1,就是「个人 AI 硬件」的起点。