-
传感器(Sensors):先进的传感器通过视觉、LIDAR/RADAR、触觉和音频输入使机器人能够感知和解读环境。这些技术支持机器人实现安全导航、精准操作以及情境感知。
-
嵌入式计算(Embedded Computing):设备上的CPU、GPU和AI加速器(如TPU和NPU)能够实时处理传感器数据并运行AI模型,实现自主决策。可靠的低延迟连接确保了无缝协调,而混合边缘-云架构允许机器人在需要时卸载密集型计算任务。
随着硬件的日益成熟,行业的关注点转向了构建“机器人大脑”:强大的基础模型和先进的控制策略。
在AI整合之前,机器人依赖基于规则的自动化,执行预编程的动作,缺乏自适应智能。
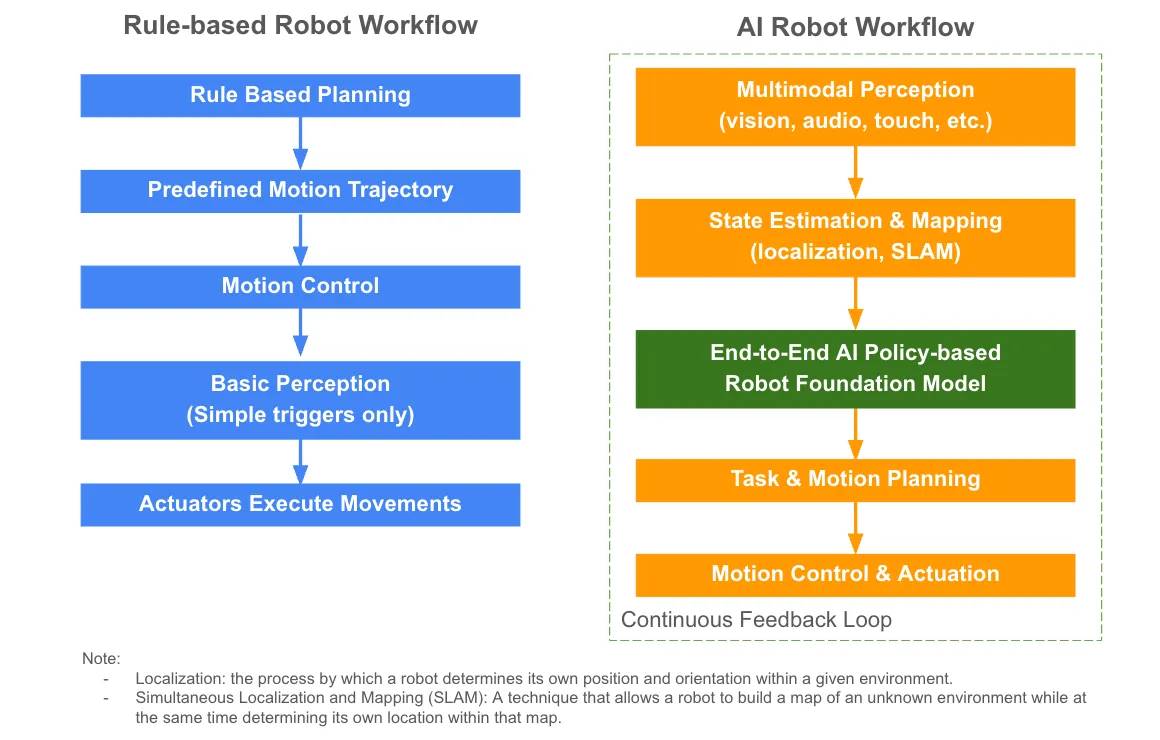
基础模型正在逐步应用于机器人领域。然而,单靠通用的大型语言模型(LLMs)还远远不够,因为机器人需要在动态的物理环境中进行感知、推理和行动。为满足这些需求,行业正在开发基于策略的端到端机器人基础模型。这些模型使机器人能够:
-
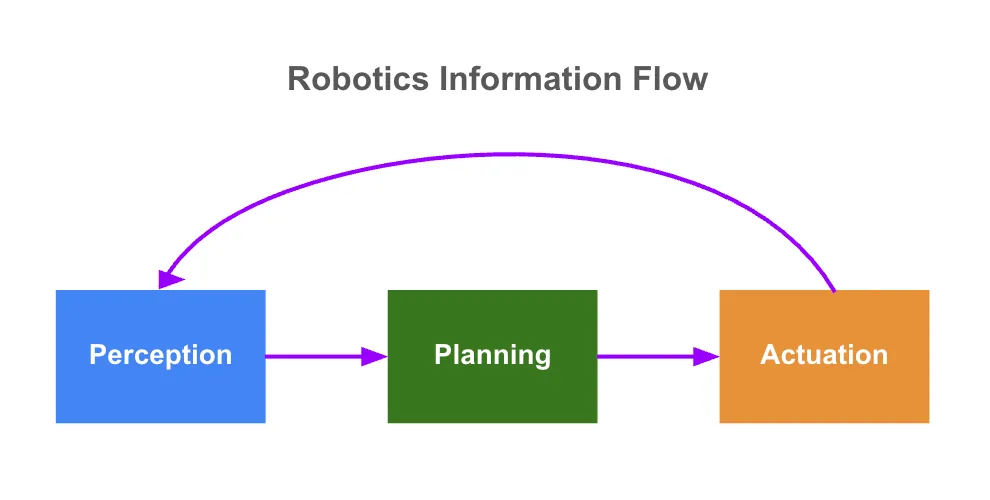
感知(Perceive):接收多模态传感器数据(视觉、音频、触觉)
-
规划(Plan):估算自身状态、绘制环境地图并解释复杂指令,将感知直接映射到行动,减少人工工程干预
-
行动(Act):生成运动计划并输出控制命令以实现实时执行
这些模型学习与世界交互的通用“策略”,使机器人能够适应各种任务,并以更高的智能和自主性运行。高级模型还使用持续反馈,让机器人从经验中学习,从而在动态环境中进一步增强适应能力。
VLA 模型将感官输入(主要是视觉数据和自然语言指令)直接映射到机器人行动,使机器人能够根据“看到”和“听到”的内容发出适当的控制命令。值得注意的例子包括谷歌的 RT-2、英伟达的 Isaac GR00T N1,以及 Physical Intelligence 的 π0。
为增强这些模型,通常会整合多种互补方法,例如:
-
世界模型(World Models):构建物理环境的内部模拟,帮助机器人学习复杂行为、预测结果、规划行动。例如,谷歌最近推出的 Genie 3 是一个通用世界模型,可以生成前所未有的多样化交互环境。
-
深度强化学习(Deep Reinforcement Learning):通过试错帮助机器人学习行为。
-
远程操作(Teleoperation):允许远程控制并提供训练数据。
-
示范学习(LfD)/模仿学习(Imitation Learning):通过模仿人类动作教授机器人新技能。