其架构可以分为三层:
-
日志层(Log Layer):实现非结构化数据的永久存储,适用于归档或数据日志等用途。
-
键值存储层(Key-Value Layer):管理可变的结构化数据,并支持权限控制,适合动态应用场景。
-
事务处理层(Transaction Layer):支持多用户的并发写入,提升协作和数据处理效率。
随机访问证明(Proof of Random Access, PoRA)是 0G Storage 的关键机制,用于验证矿工是否正确存储了指定的数据块。矿工会周期性地接受挑战,需提供有效的加密哈希作为证明,类似于工作量证明。为确保公平竞争,0G 对每次挖矿操作的数据范围限制为 8 TB,避免大规模运营商垄断资源,小规模矿工也能在公平环境中参与竞争。
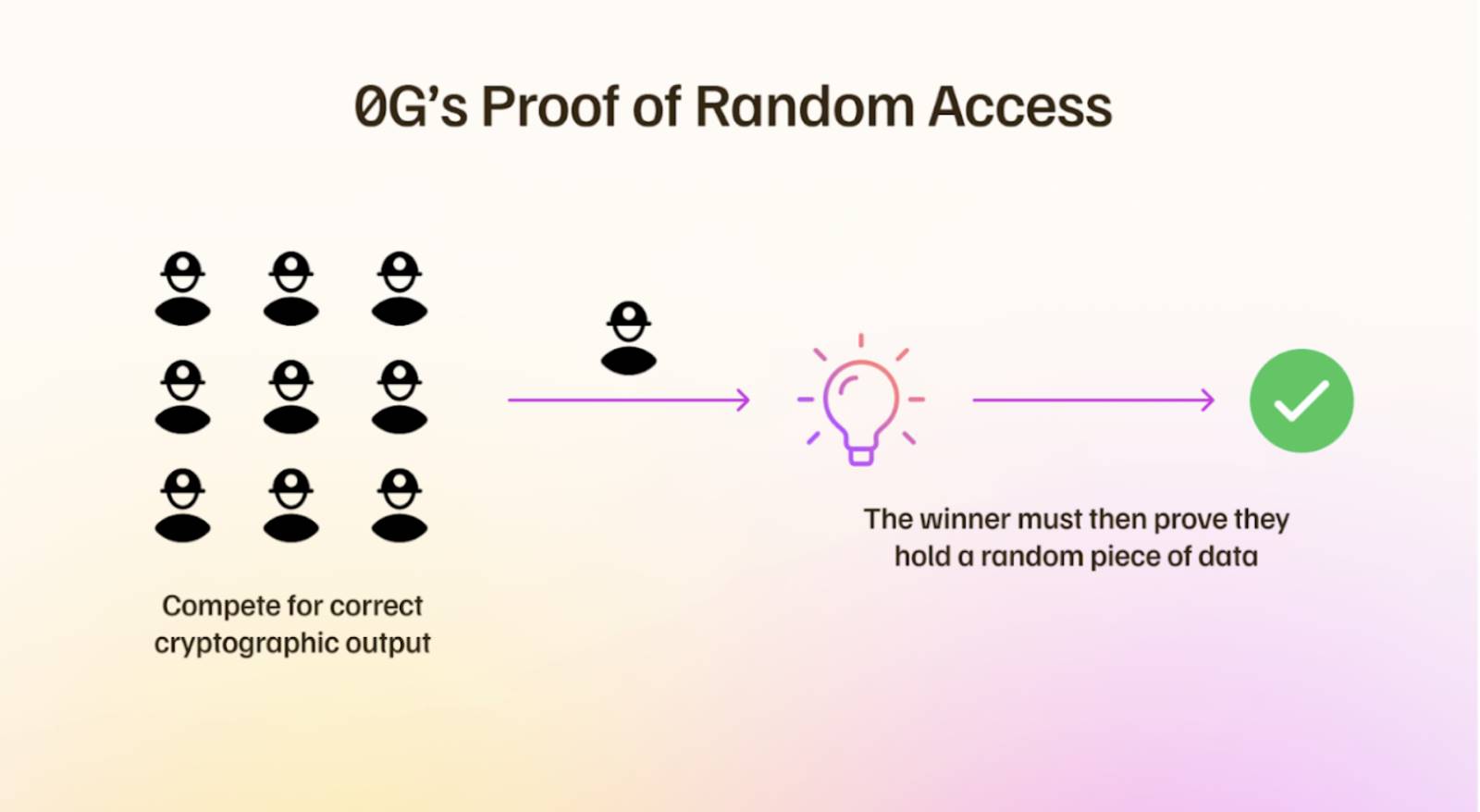
随机访问证明示意图
通过纠删编码技术,0G Storage 将数据分割成多个冗余的小片段,并分布到不同的存储节点上。这种设计确保即使部分节点下线或发生故障,数据仍然可以被完整恢复,不仅显著提升了数据的可用性和安全性,还使系统在处理大规模数据时表现出色。此外,数据存储通过扇区级和数据块级的精细化管理,不仅优化了数据访问效率,还增强了矿工在存储网络中的竞争力。
提交的数据以顺序方式组织,这种顺序被称为数据流(data flow),可以被理解为日志条目列表或固定大小数据扇区的序列。在 0G 中,每一块数据都可以通过一个通用的 偏移量(offset) 快速定位,从而实现高效的数据检索和挑战查询。默认情况下,0G 提供一个称为 主数据流(main flow) 的通用数据流,用于处理大部分应用场景。同时,系统还支持 专用数据流(specialized flows),这些数据流专门接受特定类别的日志条目,并提供独立的连续地址空间,针对不同的应用需求进行优化。
通过以上设计, 0G Storage 能够灵活适配多样化的使用场景,同时保持高效的性能和管理能力,为需要处理大规模数据流的 AI x Web3 应用提供强大的存储支持。
0G 数据可用性(0G DA)
数据可用性(Data Availability, DA) 是 0G 的核心组件之一,旨在提供可访问、可验证且可检索的数据。这一功能是去中心化 AI 基础设施的关键,例如验证训练或推理任务的结果,以满足用户需求并确保系统激励机制的可靠性。0G DA 通过精心设计的架构和验证机制,实现了出色的可扩展性和安全性。
0G DA 的设计目标是在保证安全性的同时提供极高的扩展性能。其工作流程主要分为两个部分:
-
数据存储通道(Data Storage Lane):数据通过纠删编码技术被分割成多个小片段(“数据块”),并分布到 0G Storage 网络中的存储节点上。这种机制有效支持了大规模的数据传输,同时确保数据的冗余性与可恢复性。