一种理解方式是采用 AI 研究人员最喜欢的技术:趋势外推。以下是基于 GPT 深度研究调查的趋势线,假设采用顶级安全技术,每千行代码的漏洞率随时间变化如下。
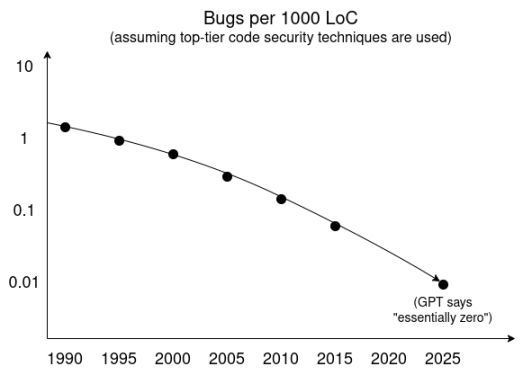
此外,我们已看到沙盒技术及其他隔离和最小化可信代码库的技术在开发和消费者普及方面取得显著进步。短期内,攻击者独有的超级智能漏洞发现工具能找到大量漏洞。但如果用于发现漏洞或形式化验证代码的高度智能代理是公开可用的,那么自然的最终平衡将是:软件开发人员在发布代码前,通过持续集成流程发现所有漏洞。
我可以看到两个令人信服的理由,说明为什么即使在这个世界上,漏洞也无法完全消灭:
-
缺陷源于人类意图本身的复杂性,因此主要困难在于构建足够准确的意图模型,而非代码本身;
-
非安全关键组件,我们可能会延续消费科技领域的既有趋势:通过编写更多代码来处理更多任务(或降低开发预算),而非以不断提高的安全标准完成相同数量的任务。
然而,这些类别都不适用于 「攻击者能否获取维持我们生命的系统的 root 权限」 这类情况,而这正是我们所讨论的核心。
我承认,我的观点比当前网络安全领域的聪明人所持的主流观点更乐观。但即便你在当今世界的背景下不同意我的观点,也值得记住:《AI 2027》场景假设存在超级智能。至少,如果 「1 亿个超级智能副本以 2400 倍人类速度思考」 都无法让我们获得没有这类缺陷的代码,那么我们绝对应该重新评估超级智能是否如作者想象的那样强大。
在某种程度上,我们不仅需要大幅提高软件安全标准,还需要提升硬件安全标准。IRIS 是当前改善硬件可验证性的一项努力。我们可以以 IRIS 为起点,或创造更好的技术。实际上,这可能涉及 「构造正确」 的方法:关键组件的硬件制造流程特意设计了特定的验证环节。这些都是 AI 自动化将大幅简化的工作。
超级说服力的末日也远未到来如前所述,防御能力大幅提升可能仍无济于事的另一种情况是:AI 说服了足够多的人,让他们认为无需防御超级智能 AI 的威胁,且任何试图为自己或社区寻找防御手段的人都是罪犯。
我一直认为,有两件事能提高我们抵抗超级说服力的能力:
-
一个不那么单一的信息生态系统。可以说,我们已逐渐进入后推特时代,互联网正变得更加碎片化。这是好事(即便碎片化过程是混乱的),我们总体上需要更多的信息多极化。
-
防御性 AI。个人需要配备本地运行的、明确忠于自己的 AI,以平衡他们在互联网上看到的黑暗模式和威胁。这类想法已有零星试点(如台湾的 「消息检查器」 应用,在手机上进行本地扫描),且有自然市场可进一步测试这些想法(如保护人们免受诈骗),但这方面需要更多努力。