存储、计算、带宽和检索的作用涵盖了为我们提供当今所知的互联网所需的大部分工作。我们已经讨论了数据的指数增长,但重要的是了解当今数据的管理、存储和交付方式,以及这种情况在不久的将来是否会发生变化。
如果存储网络需要更多需求,计算网络需要更多供应,而检索网络需要密度来竞争,那么我们如何将这些服务捆绑在一起并大规模创建分散的替代方案?

去中心化计算平台正变得越来越受欢迎,这要归功于人们对机器学习认知度的提升,以及对计算资源真正价值的日益重视。从宏观角度看,计算本质上就是机器将电能转化为运算能力。更准确地说,它包括处理能力、内存、网络、存储以及其他确保程序成功运行所需的资源。
随着大模型的兴起,关于计算资源的讨论发生了显著变化。众所周知,这些模型在训练和推理阶段都需要惊人的计算资源 — — 由于具备并行处理能力,GPU显得尤为珍贵。最先进的模型需要在高性能资源上对海量数据集进行数周甚至数月的训练。
举例来说,Meta训练Llama 3.1 405B模型花费了超过6亿美元。有估算表明,大模型的训练算力需求每3–4个月就会翻一番。英伟达显然是GPU热潮的最大受益者,因为其芯片是大规模训练的主导硬件。谷歌的TPU以及苹果神经网络引擎等定制芯片也在这个领域发挥作用。
无需赘述读者们都清楚的一点:需求的快速增长已经超过了供应,导致阻碍进一步扩展的瓶颈出现。主要限制因素包括:
-
芯片供应链中断
-
制造产能限制
-
云资源短缺
-
能源和冷却限制
-
成本制约
最近一项关于数据中心规模的分析显示:”领先的前沿AI模型训练集群今年已扩展到10万块GPU,预计2025年将建成30万+GPU的集群”,而且还有更大规模集群的建设计划。就成本而言,一个10万块GPU的集群至少需要5亿美元,这还不包括维护如此庞大系统所需的费用。
与此同时,训练成本持续攀升,有人推测简单地增加计算资源来训练模型可能是唯一合理的解决方案之一。
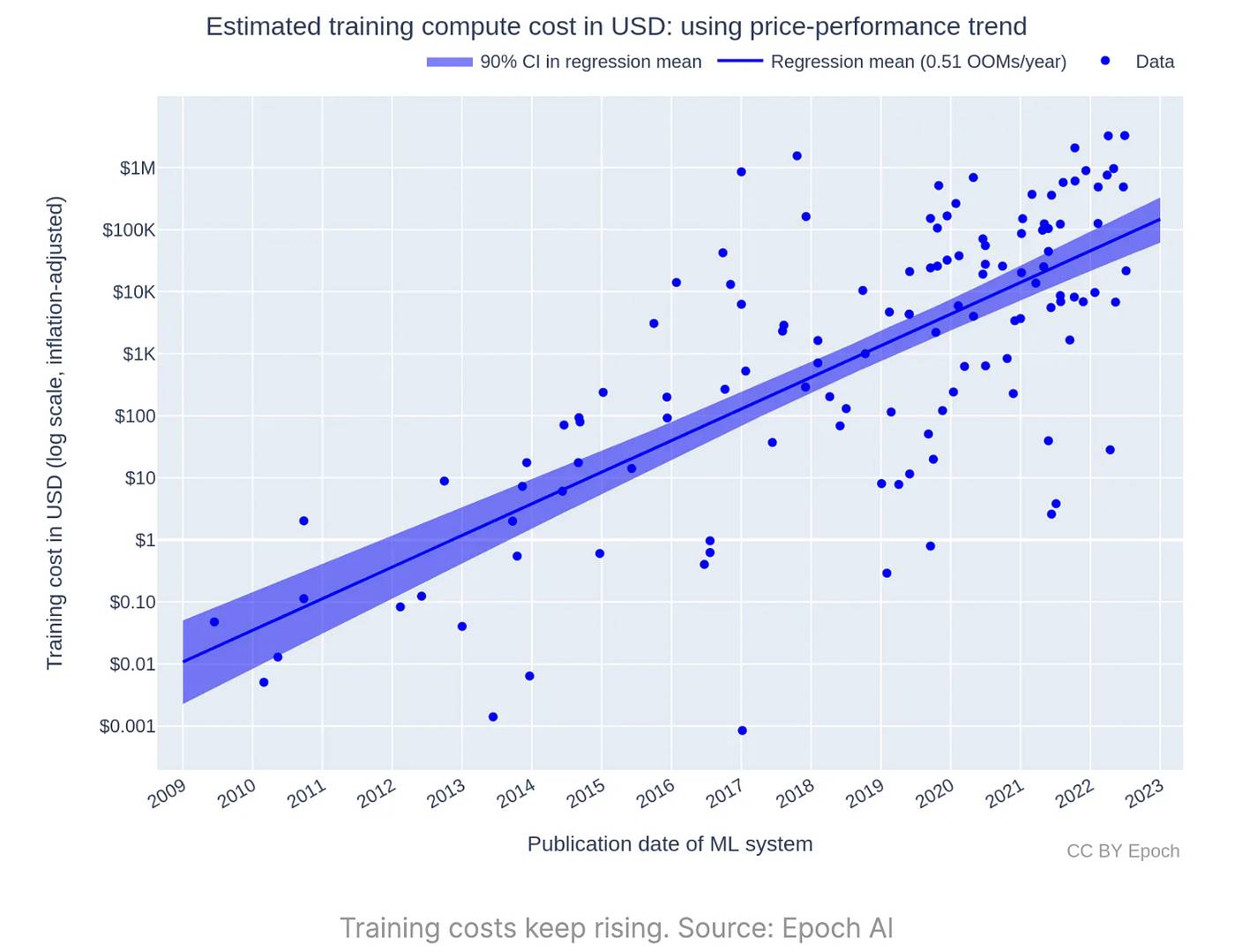
Dwarkesh Patel在2023年12月的文章中总结了这场算力竞赛:
“除了扩展模型参数本身所需的惊人算力增长(算力=参数*数据)外,让自我对弈机制运作还需要所有这些额外算力。根据对人类水平思维1e35 FLOP的估算,我们需要在当前最大模型基础上再增加9个数量级的算力。是的,更好的硬件和算法会带来改进,但真能达到整整9个数量级的提升吗?”