尽管存在诸多限制,但这恰恰意味着机遇。提高这些大模型的计算效率和可及性才是前进方向,我们已经看到了不同的解决方案。模型效率研究包括模型剪枝和知识蒸馏等技术,旨在减少推理所需的参数和操作。开发稀疏架构(每个输入只激活部分神经元)是另一个提升效率的途径。
在硬件方面,全球顶尖公司都在开发专门针对AI工作负载的专用硬件。我们近期重点关注的另一个领域是光子计算— — 这种使用光子而非电子处理数据的方法,能显著降低能耗并加速数据传输,特别适合大规模AI训练。
最后且与本报告最相关的是分布式计算。除了利用闲置计算资源这一显而易见的好处外,如果无法用于模型训练,这些资源又有何用?我们所说的这个过程被称为去中心化(或分布式)训练,作为替代中心化AI实验室黑箱开发的方式,这个话题正变得越来越引人关注。
去中心化训练可以采用多种方法来更好地利用异构计算资源训练模型。虽然目前没有适用于所有分布式训练场景的通用方案,但很可能(甚至在不久的将来)就能找到解决方案。一些较流行的方法包括DiLoCo、DiPaCo、SWARM并行等。
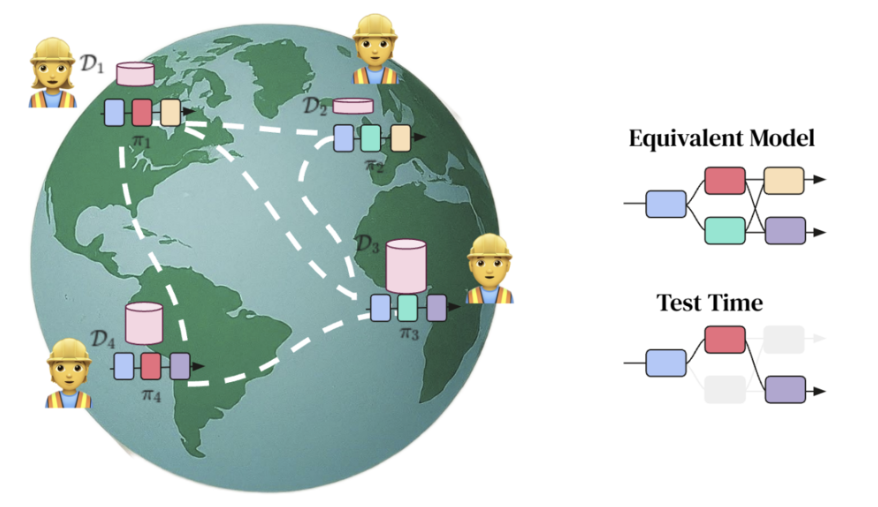
这些分布式训练方法基于并行计算理念,主要分为三类:数据并行、张量并行和流水线并行。标准GPU集群是将大量GPU集中部署在单一位置,以提供最大计算能力。但如前所述,单个地点可部署的GPU数量受物理条件限制。
分布式训练通过将传统GPU集群的能力分散部署来解决这个问题。这是一个活跃的研究领域,与这些协议正在进行的工作直接相关。即使Akash或IONet目前尚未训练自己的大语言模型,分布式训练的突破也很可能赋予它们这种能力。
这里存在一个假设:如果通过代币合理激励个人为全球市场提供优质算力,需求端自然会出现 — — 但这仍取决于协议管理异构计算资源的能力,以及实际应用前述训练方法的水平。具体实施和内部执行能力才是关键所在。
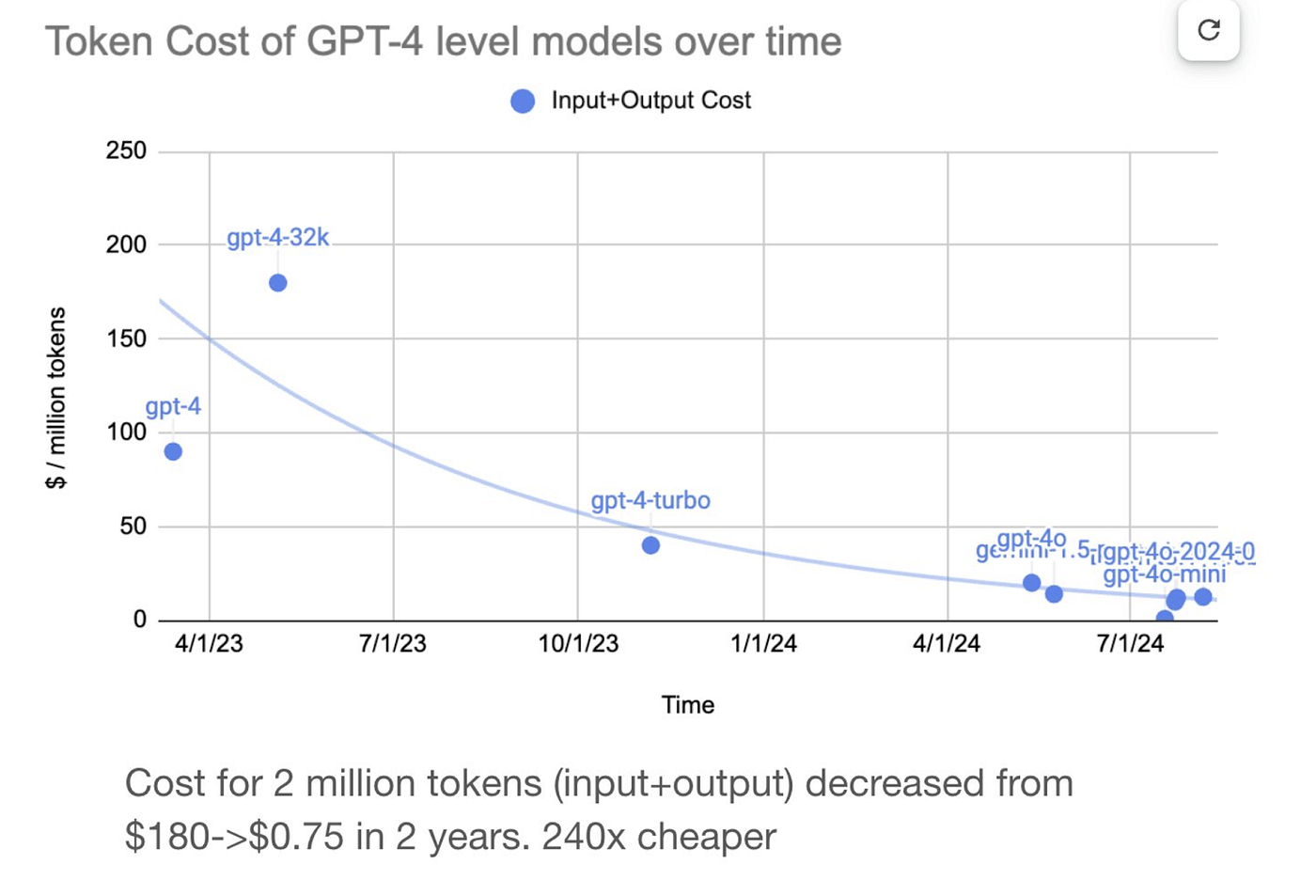
与此同时,代币成本正如预期般急剧下降。假设这些成本持续趋近于零,就应该(也将会)探索更多分布式训练方案。如果创建新大语言模型的每个步骤都变得极其廉价,但完全依赖计算资源获取,那会怎样?
去中心化可以提供更好的资源分配、扩大奖励范围并防止中心化垄断。但如果实际性能不达标,这些都毫无意义。最直接的挑战在于延迟和通信开销 — — 比如在深度学习训练中跨节点同步计算会引入效率损耗。